
Welcome!
I’m just a search engineer. A programmer. I take things that people dream up and make them reality. My background is most definitely NOT search engine optimization. But the story of how I got here, and the search engineer perspective that I’ve obtained, may be of value to you.

My name is Scott Stouffer. I’m a Carnegie Mellon University grad who hasn’t stopped coding since I got my 1st Commodore 64 when I was 6. I love music, sports, farming, texas hold’em, flying airplanes + skydiving. I started programming when I was six years old. My family decided that a Commodore 64 would be a great Christmas gift one year, and boy were they right! Within a year I was learning BASIC so I could program hundreds of fun games that only existed in a programming book. I would spend 40 hours programming a game and then the power would go out. Because the Commodore 64 didn’t have any internal memory, if the power went out that meant the entire program was lost. I would sometimes write thousands of lines of BASIC code two or three times before I finally was able to play the game that I was programming.

I learned to program very fast because of this. The faster I could code, the less likely the power would go out and cause me to dance again with deja vu. This would serve me well later on in my adulthood, as I became well known for being the guy who could turn a late-night conversation about “wouldn’t that be cool if” into a real tangible thing the next day.

I actually didn’t get my degree in Computer Science. I’m not sure why I decided against that — probably because I thought I knew everything I needed to know about that subject. Thankfully, during my five year stay at Carnegie Institute of Technology at Carnegie Mellon University, while pursuing my B.S. and M.S. in Electrical + Computer Engineering degrees, I was exposed to a number of very high quality Computer Science courses.

At Carnegie Mellon, I was lucky enough to partake in one of the very first Java classes in 1996. For our final, we built a client-server poker system (a common theme throughout my stay at CMU would be that if I had just taken any of these ideas and commercialized them, I would have been all set!). I was exposed to an amazing variety of Computer Science curriculum whenever it intersected my Electrical + Computer Engineering studies. I did some pretty cool stuff while I was there: I once wrote a program, using the concept of annealing metal, to find the most efficient way to rearrange CMU’s final exams scheduling for everyone on campus.
I had started focusing in on embedded systems design, computer/chip architecture, and digital communications (cell and satellite) design. But not all was hunky dory. The very same personality that caused me to write code faster than anyone else, also caused me to get into trouble. You see, I have always had an obsession with writing code / designing systems and not enough focus on making sure I knew what would happen if I unleashed that stuff. By my junior year at CMU, I had managed to bring down the entire CMU bandwidth while hosting my own server in my dorm room. Three steps forward, one step back. This is basically the story of my life.
Coming out of Carnegie Mellon, I chose to work down in South Florida at IBM, mostly because of the weather and the fun team there. I got my pilot’s license in 1998 during my lunch breaks. I would take off at 11am and race over to the airport and do 2 hours of flying each day. Then, one day, I got a call from a fellow Carnegie Mellon alum about doing a startup in California. They wanted me to write software for an enterprise-grade locations-based software company. Somehow, the universe found my way back to software.

I spent the next five years learning about the startup world, and how to build scalable software systems. I had lunch in the same places as the guys down the street working at a small company called Google. They were writing most of their code in Python and C++, and I was a Java guy. I loved their idea, and thought they were way better than Altavista. How ironic that I would, a decade later, be building my own search engines to show people how Google worked.
In 2004, I started gaining an interest in the stock market. After realizing that I could built automated trading systems using previous trading data, I dedicated a period of my life to cracking the NYSE and NASDAQ.

It turned out that programming skills was only one of the pieces to success there — the other was broker / floor connections.

In late 2006, I met some business owners who had decoded Google. They had figured out how to outrank the national hotels in their local market and late one night whispered a fateful question: “could this be scaled to work across the entire country?” They called their tricks “search engine optimization” or SEO for short. I told them I’d take a look.
The next day, I had designed a program in Java that could parse all of the nationwide hotel data and build out an entire website that used their same techniques to place them in the #1 position in every market. This wasn’t my first experience with how powerful my coding skills, applied the right way, could turn my thoughts into cold hard cash.

I had a bunch of friends at Google by this time, and thought it was hilarious that I was playing this cat and mouse game with them. Me writing code to find loopholes in their algorithm, and then them catching on to me and issuing an “algorithmic update”. I had unknowingly unleashed the first major link network on the Internet.

There were a number of Google algorithm updates named after stopping my code over the first year, one of which was a fairly significant design change that Google made, called the “Supplemental Index”. I knew this wasn’t a long-term business model, and quickly realized that many others would eventually follow my path, however technical or non-technical.
Because of this, I decided to switch teams, so to speak. Instead of trying to attack Google’s algorithms, I wanted to join them and show others how attacking Google’s algorithms was a fruitless short-term exercise. I wanted to build a business around showing others how to make money playing nice with Google. From my perspective, it was only a matter of a few years before Google algorithmic loopholes were even a thing. I didn’t know it at the time, but Google’s adoption of artificial intelligence would eventually make my premonition mostly come true.

Back to that first explanation I gave you. I’m just a search engineer. A programmer. I take things that people dream up and make them reality. And that was the case again here. I knew I wanted to switch sides, but didn’t know how or what to build to do that. There was another programmer building a thing called Website Grader at the same time we decided to make this business model shift. But we saw Website Grader as an artificial tool — something that wouldn’t be able to function with a future version of Google.
It was actually my wife who one day just finally said it: “why don’t you just build a search engine?” Now here’s the thing. Usually the “what if” hypotheses are typically a bit more narrow than that. “What if we could build a tool to do this” type of things. Not a freaking entire search engine. I think I spent the next few hours screaming at everyone about how crazy an idea this was, and that how one person (I was still the only software engineer) could not build an entire search engine. As with every idea, my mind started to solve the little pieces first.
At 1am that night, I woke up in a sweat. I ran into the office and starting writing on notepad. I’m not sure if I was fully conscious at that moment — it was a long time ago, but I kept those historic scribbles:
Frantic night…things are coming together very quickly….:
Start with just 1 SearchResultBean, so we can throttle requests. Present a “Google-like” GUI (interface) complete with look & feel of our company.
The scribbles went on for pages… I actually hadn’t read them in maybe ten years. It brings back a lot of memories and makes me a bit emotional. I was crazy enough to even attempt to start building a Google-like search engine. I was working a normal day job at the time. Well, normal for software engineers. 7am to 7pm, and then a quick dinner, then back to coding my search engine until 1am. Sleep, wake up, and do it all over again. I think I spent about 120 hours a week for the next two years, taking two steps forward, and one step back…many times over.
You see, I’ve found that my brain works different than others. Many engineers reading this will nod their heads. I am able to, very quickly and efficiently, parse out big problems into what we call “first principles” (think of this as the building blocks). It was this ability that primarily enabled me to break apart the basic components of Google, and build what essentially became a “generic” search engine — something that had all the major components of Google.
I started out building the search engine crawling component. Back then, there were no open source libraries to do what we were doing. I wrote almost everything from scratch. I had to figure out how to build a scalable crawler that could essentially crawl the entire Internet. This was before Ahrefs, before Open Site Explorer, even before Yahoo Site Explorer!
Next was the linking component. Google’s now expired PageRank patent had broken new ground in 1998, and turned the search industry on its head. The PageRank patent was able to more efficiently calculate the “importance” of web pages by their citation structure.
I knew that our search engine would need to show this very important piece, and so the work began.
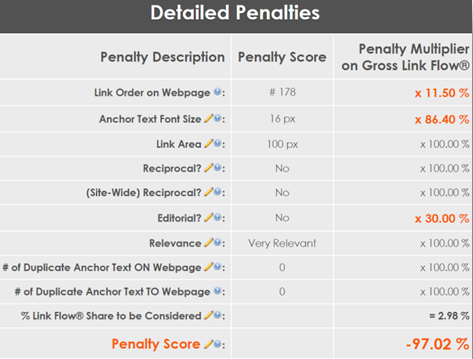
Next was the content structure and how a search engine viewed things like the META information and content on the page itself. The scoring engine, or the algorithms responsible for filtering out the younger versions of myself from attacking loopholes, had to be put in place. The run-time query stack, or the part where everything tied together to provide search results, had to be built. No open source Lucene Query Parser code was available back then.
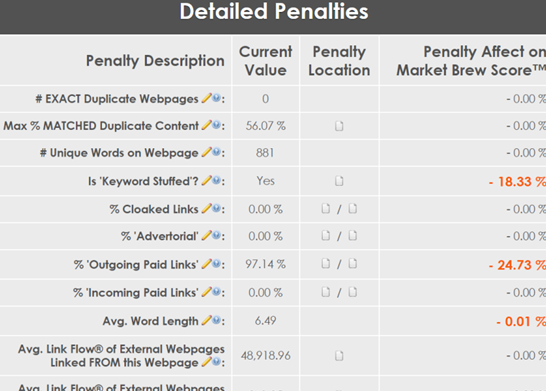
Of course, all of these things were very primitive at first, and later became very sophisticated as our product grew. I ended up writing around 750,000 lines of tightly packed code over the next few years.
And just like that, after two years, our product was BETA complete. We had filed a number of patents along the way and had drummed up our first few customers.
The first version of our product paralleled the complexity of Google at that time. We had a mostly rules-based engine that filled in the major pieces of how Google worked. Our goal as a company was to be completely white-hat: to show companies how to do things the right way, the way that Google intended for their sites to be optimized. By showing how their loophole attacks wouldn’t work, we figured that we were eventually responsible for preventing thousands, if not tens of thousands, of website owners and agencies from wasting countless hours of hopeless short-term gains only to find the rug pulled out from underneath them by a new Google algorithm update, courtesy of my old Carnegie Mellon friends.
We worked with over 64,000 users on our platform over the next five years as we went from a small retail product to a large-scale enterprise platform. As Google became less transparent, and more complex, the need for a third-party “search engine model” grew.
Around 2013, Google’s obsession with machine learning started gaining momentum. We (as well as many others) started realizing that our generic search engine approach became the primary approach to tracking the behavior and characteristics of the modern version of Google. This was because Google had shifted from a rules-based engine to a machine learning-based engine.
The new version of Google consisted of the same similar “parts”, like the well known “Panda” and “Penguin” algorithms, but the difference was each search result was scored uniquely with a specific set of algorithmic weightings. In some circumstances, one algorithm would be dominant, and in others, maybe another algorithm was dominant. This led to the breakdown of rules-based tools like Website Grader (hilariously enough, most SEO software platforms still use this very same technology). Rules-based tools need transparency into Google — they need to be able to code a specific rules set based on what they can see happening in Google.
We had anticipated the loss of transparency for the same reason why we stopped trying to attack Google’s algorithmic loopholes many years ago. We knew that Google’s engineering team would eventually come to the same conclusion — that exposing some of their ranking data was not in their technical best interests (nor was it in their business interests, when selling pay-per-click ads was over 90% of their revenue). Those in the industry will recall the “Not Provided” fiasco, as the data that was previous available started to become extinct.
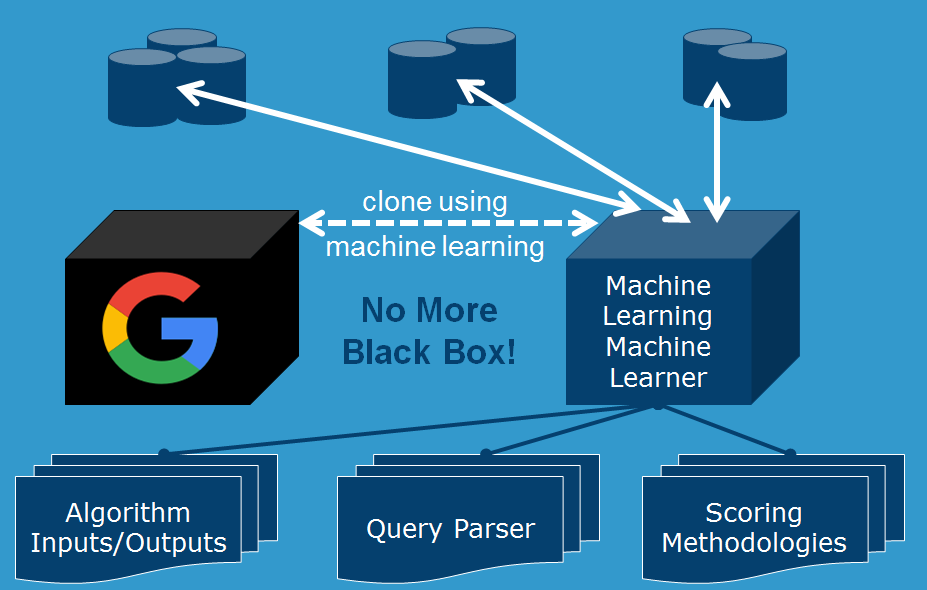
Our generic search engine was also imperiled by this move from rules-based to machine learning-based. As had been in years past, the complexity of our generic search engine modeling software grew in parallel with Google. We built a new artificial intelligence component on top of the generic rules-based search engine, which enabled us to point our generic search engine at any search engine result, and machine learn the behavior and characteristics of that environment. This meant that within a few minutes, we could turn our generic search engine into a Google simulator of sorts. Website owners and teams could make organic changes to their website code, and run that through our calibrated models to see what (statistically) would happen in a few months, once Google’s algorithms crawled their new changes.
This brings me to the current day. I’ve made my (small) mark on the SEO industry, and in my opinion, I feel like I’ve been sort of an unbiased bridge between the search engine world and the SEO world. It’s been an exhilarating ride. I’ve been able to help a lot of brands to understand what Google has been trying to do for many years — help their search engine rank the companies that play nice with Google at the top.
So why should you listen to me? I’m the guy on the other side of the fence, building search engines and algorithms. I’m one of the guys building machine learning and neural networks into search engines, and always finding ways to modernize search. I’m not really an SEO guy, although I sure do know a lot about how search engines work!
 Ask The Search Engineer on Youtube!
Ask The Search Engineer on Youtube!