
The Search Engine Scoring Layer
We talked about how important to the design the search engine indexing layer was to the scoring layer, due to the myriad of required inputs into individual algorithms that need that crawl data. The search engine scoring layer is the most high-profile layer of modern search engines, primarily because it is the layer that is responsible for the ranking of search results. It is regarded, by most non-search engineers, as a mysterious black box that befalls its fate amongst mere mortals.
Interestingly enough, for me, the scoring layer was both the easiest and most enjoyable part of the search engine to build. I won’t go into the specifics (programming languages, libraries, etc…) here, just the things I wish I had someone tell me when I built my first search engine.
In 2006, when I started building my first search engine, Google was a rules-based engine that could be reverse engineered pretty easily by someone with my skills. In fact, I believe today that things would be a bit harder to start from scratch simply because the template that I used, Google, has its scoring layer not entirely rules-based anymore.
The scoring layer is responsible for two major things:
- Pre-calculating data / scores to be used at run-time when a user queries the search engine, and
- Identifying and eliminating spammy web pages that in the end will degrade the quality of the search engine’s user experience.
At its core, the search engine scoring layer works on a link graph, with nodes that are typically represented as web pages. The links between these web pages and their relative importance are critical in understanding how modern search engines rank those pages.

An example of a link graph.
The first scoring layer algorithm we created at Market Brew was what we called the link flow distribution algorithm. The goal is simple: given a set of web pages, determine their relative importance to each other. Larry Page had come up with a brilliant idea that this calculation could be based on the citation structure that academic white papers were based on.
Sergey Brin of course argued that this could be done with a lot of fancy math, or what us math majors call eigenvectors. The layman’s way to think about it: given a human who starts at a random URL on the Internet, what is the probability that he lands on each web page of the Internet by clicking the links on each page?
Of course, when you load a web page on your browser, you don’t have the same probability that you will click on each link. Some links are more likely to be clicked on. And this is the beginning of the search engine scoring layer.
Link Algorithms
Not all links are created equal…and as a search engine engineer, you must come up with a way to classify which links are more important than others. This is not a digital calculation, but an analog one.
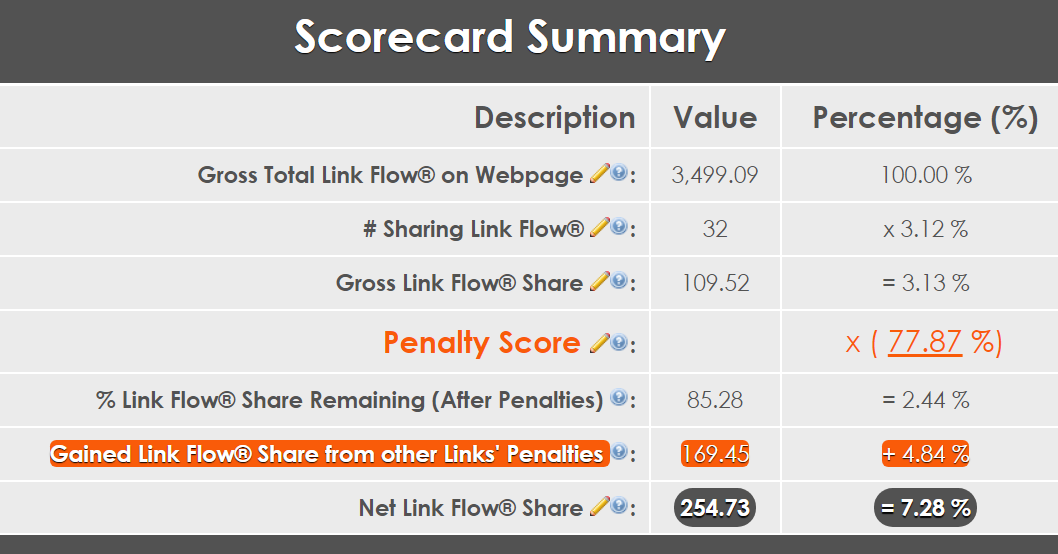
An example of how a search engine scores an individual link.
The above image is an example of the overall process of scoring one link. This process must be done for each link on every web page on the link graph. It goes like this:
- Seed each link with equal importance.
- Apply a link algorithm to penalize a specific link characteristic. For example, the largest link on the page gets a 100%, and the smallest link on the page gets a 50%.
- Iteratively redistribute the lost link values to the rest of the links on the page, according to the new scoring hierarchy.
- Repeat #2 until all link algorithms have been exhausted.
At the end of this you will have a hierarchy of links on the web page. This is one of the most taxing processes of the scoring layer there is. Here’s why…
Many of the link algorithms actually depend on the link hierarchy. But wait, we need the output of the link algorithms to determine the hierarchy! How can this be? Here’s an example: one of the things we can anticipate as search engineers is that some links are probably more relevant to the content it is linking to, than other links.
We can come up with a link algorithm to sort this all out; a relevance algorithm that simply compares the anchor text in the link to the semantic meaning of the target page. All we have to do is calculate the target page’s meaning by looking at the content on the page as well as what others think the page is about (the anchor text and relative link value of the links pointing to that target page). Of course, to do this we need to calculate the relative link values first, but wait…
You will find that there are a lot of these situations in the search engine. One algorithm depends on another which depends on another which depends on the first algorithm! Fortunately, there are iterative ways to calculate this stuff, but that means that each link scoring pass that we do is sometimes not trivial.
Other challenges that you will run into are related to database retrieval times. There are trillions of links in some web page link graphs. One database request to get, say, all of the links with similar anchor texts, taking 10 milliseconds times a trillion iterations is 316 years! So a lot of data needs to be pre-calculated and/or cached in memory to drastically reduce retrieval times for simple operations. Shaving off one millisecond can reduce scoring times by hours.
Here’s an example of some of the link scoring algorithms that I’ve added to search engines in the past:
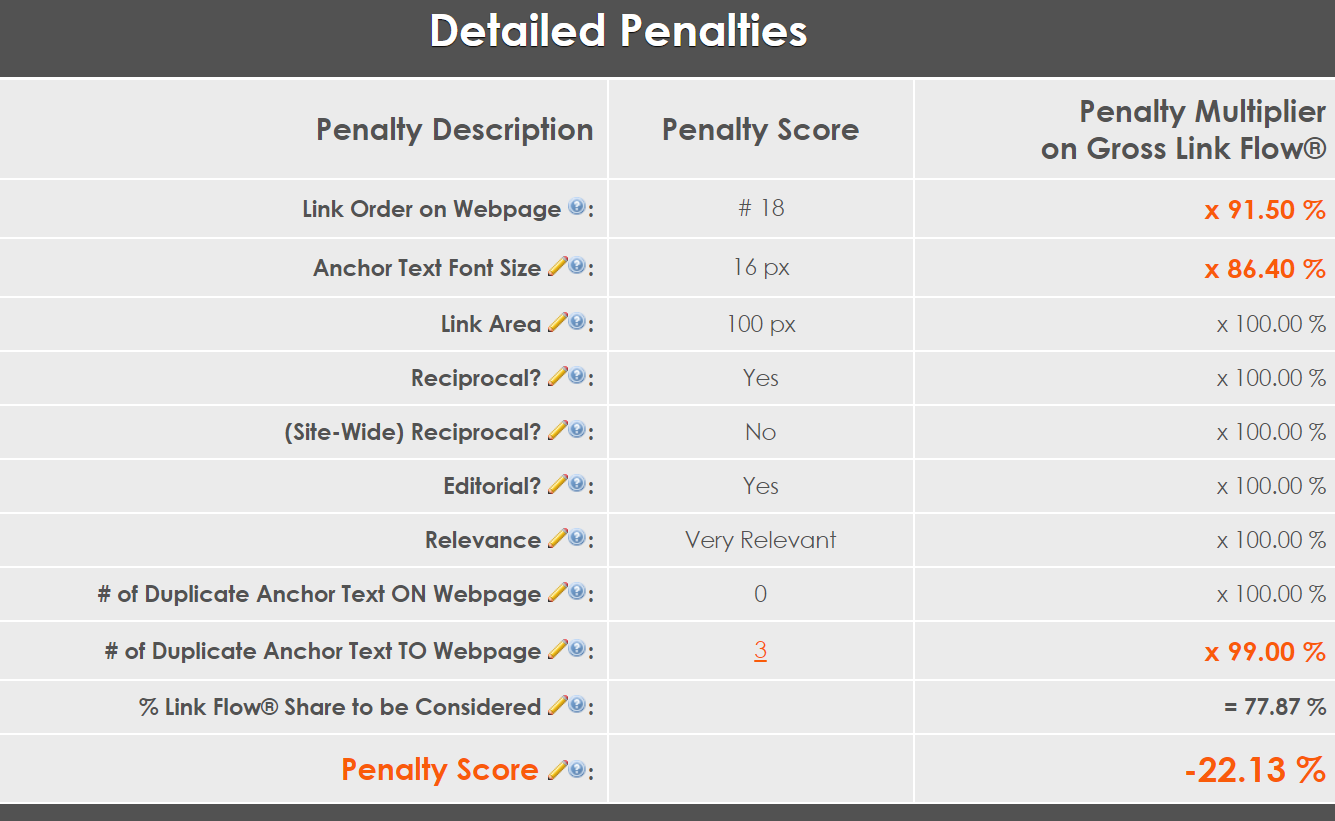
An example of the types of link algorithms that are used in a modern search engine.
You can use any link characteristic you want, as long as you ensure that it cannot be easily manipulated by humans (otherwise, that algorithmic ranking signal will be useless).
Generally, all link scoring is a zero sum game: penalizing links for a relative weakness to other links results in that link’s value transferring to other links on the page. In other words, the web page’s starting link value is preserved through the value of each link on that page. Usually.
I say generally because some search engineers at Google, in their infinite wisdom (just kidding guys) decided that they would allow website owners to add attributes to their links to indicate how important they thought those links should be. Of course, all of us search engineers later learned that this is a very, very, very bad idea. Why? Because any algorithm that can be manipulated by humans will eventually become useless due to exploitation by bad actors (we call these “black hat” search engine optimizers, or those who try to take advantage of a loophole in the algorithm to benefit in ways that the algorithm did not intend).
I am of course talking about the “nofollow” attribute on links. Some people realized that this was an easy way to “sculpt” the relative link values on a page. The search engineers at Google realized this and decided to penalize anyone abusing this attribute. Their solution: any links with this “nofollow” attribute would be penalized like any link algorithm, but instead of that link value flowing to other links on the page, it would simply evaporate.
So there are always exceptions to the rules it seems, much like hacking together a software fix to a bug, sometimes there are edge cases in the search engine link algorithms.
Once you have completed this significant step in building your scoring layer, you are ready to move to the next step…
Calculating the Link Flow Distribution
Once we have the relative importance of each link calculated, we can apply the PageRank algorithm to the entire link graph. I won’t go into the math behind this as it is, like all elegant mathematical solutions, very straightforward. The challenge with large link graphs is memory management, as much of the data needs to be stored in volatile memory in order to make the calculation reasonably quick.
Here is an example of a visualization of the resulting link graph:
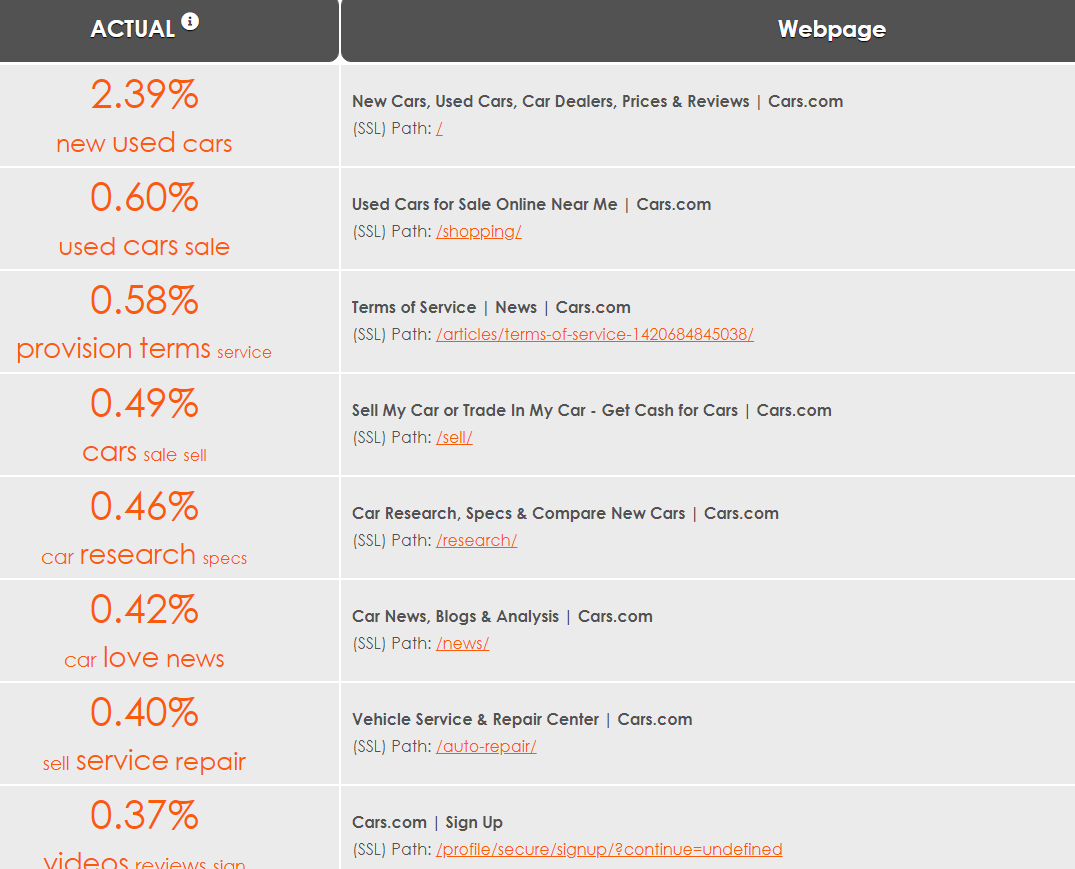
An example of how to visualize link flow distribution.
Each node (web page) in the link graph will have a probability value. In the screenshot above, we’ve converted that to a percentage of importance in the entire set of pages. For instance, in this link graph of the cars.com website, the home page receives 2.39% of the link value from all other pages in the site.
Your link graph can be of the entire Internet (for relative domain metric), an entire website (for a relative page metric), or simply a subset of web pages. It depends on what ranking signals you need for your run-time query layer.
Note that the values determined here could impact some of your link scoring algorithms! For instance, if you wanted to evaluate a link “neighborhood” to understand if you should trust the web page that this link is on, you may want to understand the page’s relative value according to this link flow distribution concept.
The linking algorithms and their recursiveness will make your head spin. But once you’ve mastered this component of the scoring layer, you are ready to move on to the next step…
Web Page Scoring Algorithms
Up to this point, we have a good idea of the citation ranking structure based on the linking architecture of your link graph. For the web pages in the graph, we could consider this a gross figure, or before any kind of web page filtering in your index.
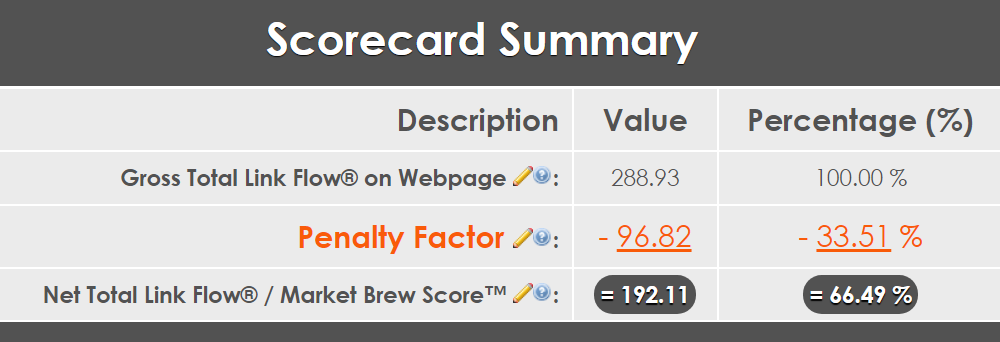
An example of how a search engine discounts a web page by applying SPAM-filtering algorithms.
If we consider what we’ve done up until now the gross figure, then we can characterize the net figure as after we apply spam filters / algorithms.
I talked about how the scoring layer was the easiest layer to build for me. This is partly because I was a math major, and partly because I entered the game at the right moment. So much of everything has to do with good timing, and my story was no different.
In the mid-2000s, the most sophisticated search engine (Google) was still relatively (to a software engineer) not that sophisticated. It was almost entirely a rules-based engine. On top of that, many of the modern spam algorithms had not yet been implemented. I started building my first search engine with Google as a guide template.
Some of the first, most simple algorithms were simple if/then equations. Things like checking META Titles/Descriptions/Keywords were missing, duplicate, oversized or undersized. Basic structural DOM stuff that Google was demanding at the time. I would build these things first, and see if my search engine matched the output of Google’s. As time progressed, and Google’s search engineers got smarter, I too picked up on the additional algorithms entering the search world.
Things like duplicate content, duplicate semantic structure, and link farms were all algorithms introduced around the time I was building version 2.0 of my search engine. As the output of my search engine started to diverge from Google’s output, I would have plenty of time to test out which missing algorithms to add to my search engine to bring them back into sync. Paid link algorithms, advertorial page detection, cloaked content detection, reading level detection — all of these types of algorithms were rolled out one by one, allowing me to iteratively gauge the relative settings of one family of algorithms against the other.
I was lucky enough to get grandfathered into the game by serially allowing me to determine each algorithm’s limits and constraints as I rolled in each one into my search engine. Today, it would be a much tougher task. You can still identify the basic families of algorithms and start from there. You don’t have to have every single one to have some success with your search results.
The key today is to build a regression test harness that allows some sort of correlation / calibration process between your search engine and the desired search engine results. You can effectively let machine learning select the weights and biases of each family of algorithms. Instead of guessing what the weights and biases are for each algorithm that you build into your scoring layer, simply let deep learning neural networks do the work for you there. This is something that I didn’t have in the beginning and later worked into my search engine modeling products at Market Brew.
Unlike link scoring, the spam scoring system that you design will NOT be a zero-sum game. In other words, each web page has a gross figure that is originally calculated using our previous steps of link scoring and link flow distribution. That gross figure is then devalued by a certain amount, depending on how many spam algorithms affect that web page.
The net figure that results from this part of the scoring layer will be attached to each URL, regardless of what keyword triggered its appearance in your search results. The net figure represents just one of the pre-calculated areas of the search engine that will be used in the next layer…the search engine query layer.
 Ask The Search Engineer on Youtube!
Ask The Search Engineer on Youtube!