
Using Artificial Intelligence to track the behavior of any Search Engine environment
I’m going to take off my search engineer hat and put on my search engine optimization (SEO) hat for a moment. Let’s look at how we might be able to use artificial intelligence to track the behavior and characteristics of the ever changing algorithms on a search engine like Google.
I previously talked about why Google shifted from a rules-based search engine to a machine learning-based one. Keeping up with all the various ways website owners could exploit loopholes in its algorithms was just too much. It realized that machine learning could be used to merge human “quality raters” with its algorithmic scalable approach, and so it quickly adopted this new approach.
I also talked about Google’s obsession with Neural Networks. We learned that, with the immense amounts of data at Google, it wasn’t able to define a simple linear equation to score indexed data against its many algorithms. Instead, it turned to using neural networks as a way to define very complex nonlinear equations to classify data.
We learned that it is nearly impossible now to use the old ways of SEO tools to understand what the search engines want. Each search engine environment (ranking result) is now scored differently, and these scoring algorithms are often shifting slightly each day!
Google doesn’t operate on a rules-based machine now, how could SEO teams? We need a new understanding.

Let me ask you: why couldn’t we use a machine learning model to learn what Google is preferring when ranking its index? Well, it turns out, we can use the same principles of machine learning to create a machine learning machine learner. Let me take a step back and explain first how the pieces get put together.
In Google’s case, it has a core set of rules-based algorithms that operate on an indexed version of the Internet. It is then using machine learning to adjust the weightings on those algorithms.
The labels of Google’s models are defined by its engineers (thresholds in specific algorithms) and human “quality raters” (this site looks spammy). They are a combination of regression models, answering things like “what is the probability that this link is spam?” and classification models, answering bigger questions like “is this site spam?”.
The features of Google’s models are the inputs. Things like content, links, or really anything that is indexed and/or calculated by a search engine can be a feature.
We want to build a model that can essentially reverse engineer all of this so we can understand which algorithms are more important in each search engine environment. In Google’s “black box”, they have a number of algorithms that exist. Traditional methods of rules-based SEO tools simply look at the output of the black box and try to put the proverbial finger in the wind and report back.
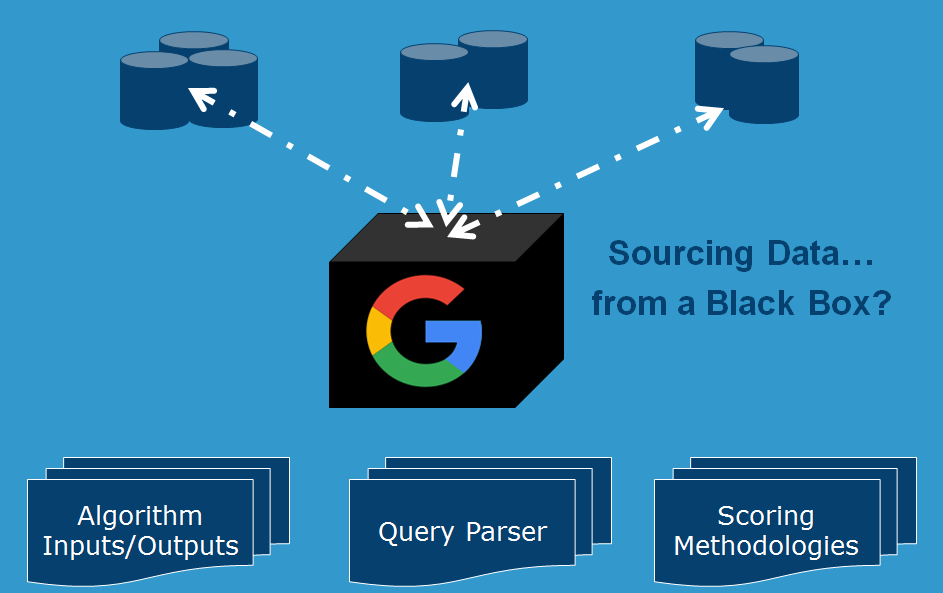
Instead, we want to try to pull apart the various components inside that black box.
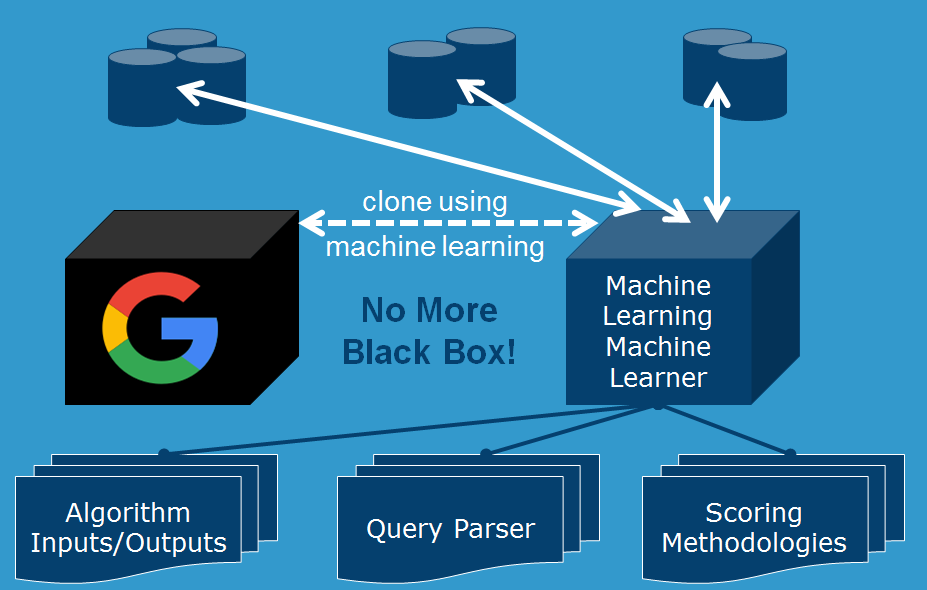
When building a machine learning model on top of that, the labels and features are different. The labels of the machine learning machine learner model become the actual ranking data or search results, and the features of the model are the algorithmic outputs themselves!
Wait, but how do we know which algorithms to add as features? In this exercise, we will assume that we have a list of algorithms that define a modern search engine. In practice, this can first be determined by starting with a basic set of known algorithms. We can use this model technique to use a trial and error method of guessing the missing algorithms in our model. Our model will tell us if there is a missing piece because the model loss will not converge. A correct missing piece will cause the models to be more accurate in predicting rankings, an incorrect one will do the opposite.
We are boiling the black box down to first principles. Before we proceed, I want to answer those of you who are screaming at their screens “but correlations does NOT equal causation!”
That is exactly correct. Correlation does not imply causation. However, it can lead us to first principles. There was a published study showing that TV sales correlated with deaths. Now, obviously, on TV sales correlated with deaths alone is meaningless. Of course, a closer look would show us that growing TV sales is correlated with a growing population (and therefore more deaths). But what if in the future TV sales flatten while deaths don’t? This relationship tells us that some new factor has disturbed the correlation, and needs investigating.
This seemingly meaningless correlation has begun to help us identify first principles.
In the same way, we can begin to break down the black box.
So we start with a “generic” search engine. One that behaves like a modern search engine like Google, and has all the basic rules-based algorithms that have been well documented through the history of modern search engines. Algorithms like duplicate content, keyword stuffing, content matching like the scoring of META Titles and HTML. Link scoring algorithms like link size, location, reciprocity, relevancy, and so on.
We have to be careful here. We don’t want our generic search engine to be too complex. This might sound counter-intuitive, but we want our generic search engine to be a simple list of basic families of algorithms. It will be the magic of machine learning that will enable us to explore the interconnections between these families of algorithms that allow us to gain clarity.
So why don’t we want our generic search engine to be too complex? Isn’t Google complex and therefore if we make our machine learning machine learner model too basic, won’t our model fail? Actually, just the opposite.
To explain this, we need to explore machine learning basics a bit further.
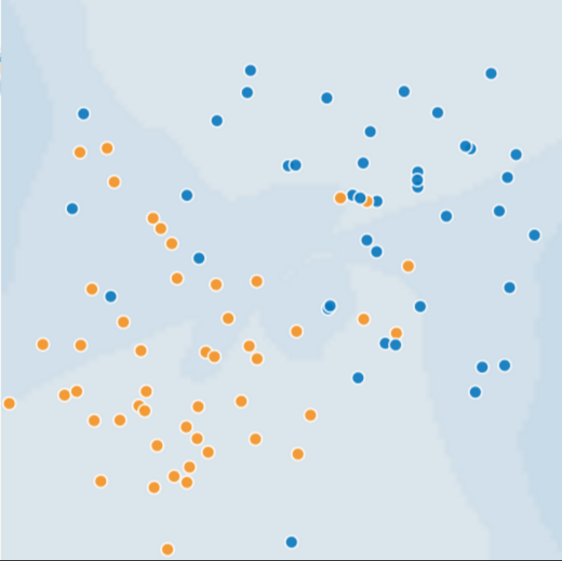
Take a look at this chart below. Let’s call the orange dots “spammy sites” and blue dots “non-spammy sites”. This chart should look familiar to you as it is very similar to the charts we discussed in my talk about why Google is obsessed with Neural Networks. In this dataset, it’d be pretty hard to find a linear line that separates the orange sites from the blue sites. Clearly a nonlinear equation (using neural networks) is a better fit:
After using machine learning and neural networks to determine a nonlinear equation for this dataset, we would come up with something like this:
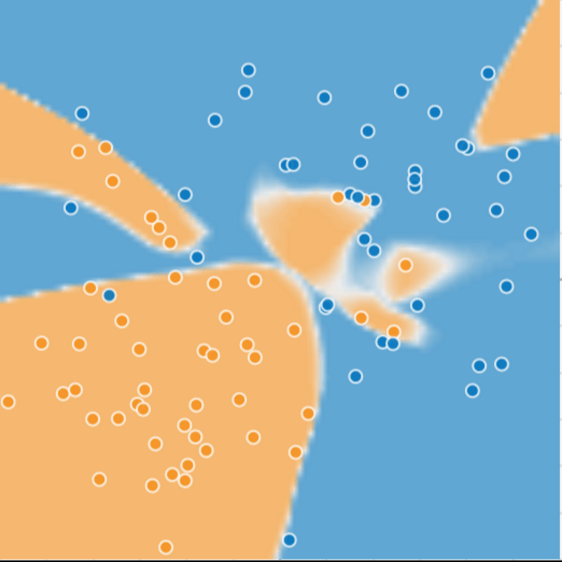
Pretty good, right?! This neural network technology is amazing! The orange and blue backgrounds are what the model predicted, and this lines up pretty well with the actual orange and blue dots/sites.
But wait, look what happens once we add new data:
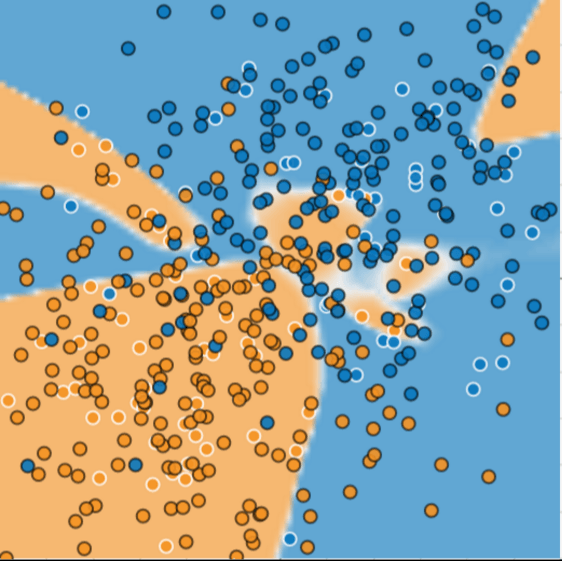
Uh oh. The new data is clearly not fitting the previously trained model. What happened here?
As it turns out, this model is actually overfitting the data. It is honing too much into the peculiarities of the dataset. This is because our model is too complex.
Remember, with neural networks, we can define as complex a nonlinear equation as we want. We can go ahead and add thousands of hidden layers and fit any dataset given, really. But this doesn’t mean that it can be useful for predicting what will happen next when we add additional data.
William of Ockham, a 14th century friar and philosopher, loved simplicity. He believed that scientists should prefer simpler formulas or theories over more complex ones. To put Ockham’s razor in machine learning terms:
The less complex a machine learning model, the more likely that a good empirical result is not just due to the peculiarities of the sample.
We’re in the same situation here with our machine learning machine learner model. We want to model Google’s mix of algorithms to determine how a ranking result is calculated. When we design a machine learning approach to this, we want to model Google as a bunch of algorithmic components that are as basic as we can make them.
This doesn’t mean that we over-simplify or don’t do the hard work of understanding the core components of a modern search engine. But it does mean that we prefer a feature set that showcases the top layer of algorithms, the ones that are immediately responsible for the inputs into the real-time query scoring engine that users interact with.
We also don’t want our model to overfit the data by allowing the weights on those features to drastically increase or decrease in order to find a fit.
In machine learning, we use something called a L2 regularization formula, which defines the regularization term as the sum of the squares of all the feature weights:
![]()
For example, a linear model with the following weights:
![]()
Has an L2 regularization term of 26.915:
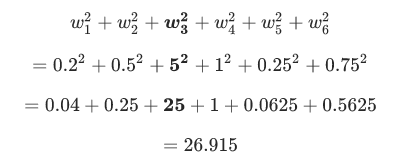
But w3 (bolded above), with a squared value of 25, contributes nearly all the complexity. The sum of the squares of all five other weights adds just 1.915 to the L2 regularization term.
In this case our model is penalized with a higher L2 value. We use regularization formulas in our machine learning machine learner to accomplish the same thing: keep our generic search engine model as simple as possible.
Obviously simple is a relative term. A modern generic search engine is going to be quite complex in itself — from crawling, indexing, scoring, and query parsing components and doing it at scale.
But once the generic search engine is in place, we can follow the basic principles of machine learning, using neural networks. For each search result, we have a list of currently ranking sites. We want our generic search engine model to output something similar, and we want to do it without over fitting the data.
- Assign a weighting placeholder to each 1st level algorithm — these are your biases that will be solved by training the model.
- The labels are already done — they’re the current search results. Note that there is a slight caveat here: the search results are typically delayed, sometimes quite significantly, from when they were actually calculated. How do we mitigate this? One possible idea would be to skip every other search result ranking. Instead of trying to fit page #1,#2,#3,#4, etc…we can instead try to fit #1,#3,#5, etc. By doing this, we are minimizing the chances that two sites very close together in ranking are trading spaces and potentially causing inaccurate loss figures in our model.
- We can use the standard Mini-Batch Stochastic Gradient Descent (Mini-batch SGD) to train our generic search engine model. When complete, we will have the correct weightings of algorithms on our 1st level of the search engine model.
Don’t forget, we need to design a neural network for all of this to work — this is a trial and error iterative process. How many hidden layers? How many neurons in each layer? What is the best activation function? How are the neurons in each layer connected?
We can use a Deep Neural Network called a Softmax that allows us to turn the labels into a probability matrix, or a fancy name for rankings. This allows us to measure how close we are to accurate rankings with our generic search engine model.
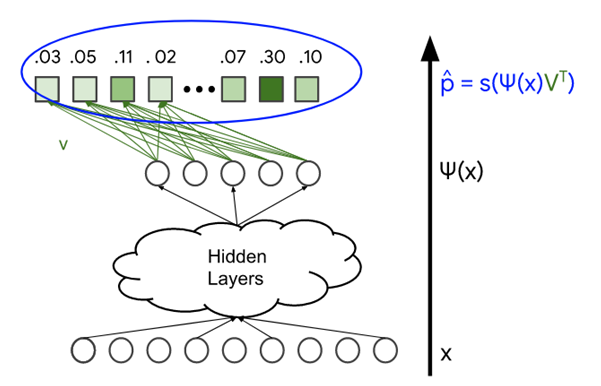
By following this general process, we have effectively created a Google Simulator of sorts. Without having to literally reverse engineer the actual rules-based algorithmic code, we can statistically simulate a close version of it, and that allows us to then explore the interconnections between each major component that our generic search engine model has exposed.
During the design of a generic search engine model, we can also use this same technique to solve individual rules-based algorithms, when we are unsure of what certain thresholds are. In this case, the thresholds are the features and the labels are going to be known.
A simple example might be an algorithm that looks at keyword overuse on a page. How much overuse is too much? We can use humans to separate a list of pages out into two buckets: spammy and not spammy. Our labels are now set, and we can begin training the model to find out what the actual thresholds should be on our complex rules-based algorithm.
As Google has moved towards a machine learning-based search engine, those very same principles can be used to provide a very organic and Google-friendly SEO environment. SEO transforms from the old black-hat environment, where the game was trying to find loopholes in a rules-based algorithm, to a white-hat environment, where SEO professionals focus their efforts on matching, stride-for-stride, Google’s focus on what makes their search engine users happy.
 Ask The Search Engineer on Youtube!
Ask The Search Engineer on Youtube!