
Why Google went from a rules-based to a ML-based search engine
“Machine Learning changes the way you think about a problem. The focus shifts from a mathematical science to a natural science, running experiments and using statistics, not logic, to analyze its results.”
Peter Norvig – Google Research Director
Search engines used to be pretty simple. Altavista, the #1 search engine in 1998, was simply an indexing and query parsing machine. It crawled content, indexed it, and then ranked query searches based on how well the query phrase matched its index. There were other, more simple search engines before that, but we don’t get into all those details right now. It was extremely easy to guess what content would rank #1 and optimize accordingly.
Then a few guys had the idea that maybe all of these links on the Internet could be used as a ranking signal. They called it PageRank, which essentially ranked pages based on an algorithm that simulated a random surfer clicking around the Internet. They found that the search rankings were so much better than Altavista, they decided to start a new search engine called Google based on this new algorithm.
Besides this new PageRank algorithm, even the early days of Google were still very relatively simple compared to today’s version. You could still easily find what caused a #1 ranking on Google. Manipulating simple things like links, content, and anchor text (the text in a link) caused most of the ranking changes.
So why DID Google take over Altavista so suddenly? To find the answer to this very important question, we must first explore the history of the search engine business model. Search engines primarily acted as an alternative to the “portal” model. With the portal model, companies like Yahoo! manually curated the Internet into categories of links for its users. With the search engine model, a computer algorithm is responsible for doing this work. As with anything automated, the search engine model quickly became a better and more efficient “front page” for the Internet. Search engines found that they could capture Internet searchers’ attention by providing an always improving user experience, or an organic link index of relevant pages that constantly improved.
Search engines that could provide a better index were highly sought after by early researchers using the Internet, and then later on by consumers searching for answers and products. At the same time, companies stood to earn huge monetary benefits by being able to rank at the top of these link indexes.
But these two driving principles are in direct contradiction to one another. Rules-based search engines are inherently exploitable — that is, if a website owner can figure out how a rules-based algorithm works, it can artificially structure its content and links to make their rankings higher than a competitor’s website who doesn’t understand the “rules”. This artificial optimization would often cause the search engine’s index to return spammy links with little or no use to the search engine user. Too much of this spammy index and users would find another search engine with a better index.
As search engines become more complex, the ability to exploit their index becomes harder. And thus their index is less spammy and more useful. These more complex search engines quickly replaced their outdated competitor’s link indexes.
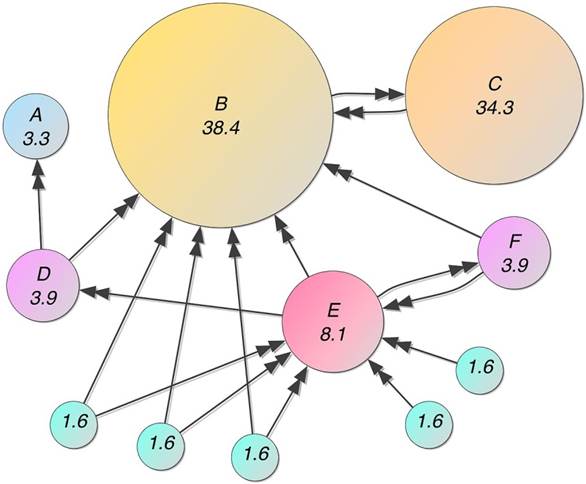
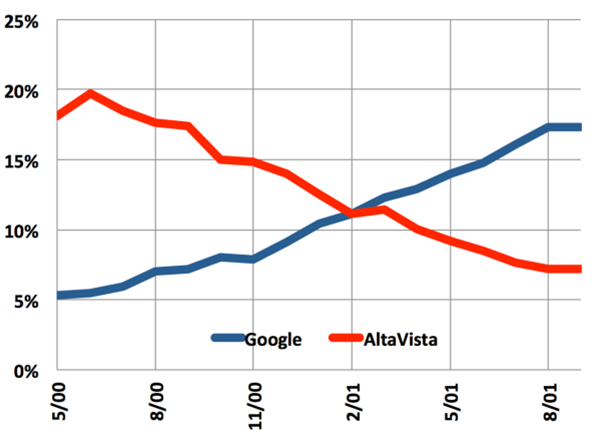
Google’s PageRank algorithm was a huge shift in complexity over the content-based algorithms. For one, the links were not totally within the website owners’ control. Their industry peers had a say in the legitimacy of a given website or web page. Exploiting linking structure was a much harder (although it turns out still very doable) problem to solve. It was with this huge firewall that Google was able to obliterate Altavista almost overnight.
PageRank was such a competitive advantage, it was like a company being able to patent the sole use of a combustion engine back in the early 1900s. And due to patent laws, it wouldn’t be until 2017 when Google would have to start worrying about someone copying this approach. During the next two decades, Google found that its PageRank algorithm was exploitable, and spent the first decade trying to outwit people like the early search engineer version of me by constantly updating and improving their rules-based link and content algorithms.
Classifying a spammy site from a useful site was something that could be easily determined by a human, but it turns out to be an extremely hard problem to solve for a computer. And so, led by engineers like Jeff Dean and Andrew Ng, Google started turning to machine learning to help them solve this classification problem.

It turns out that “supervised” machine learning is very good at solving these types of problems, with the initial help of humans. With supervised machine learning, humans first assign “labels” and “features” to a set of data. Labels are the thing that is being predicted. In search engine algorithm parlance, it could be as simple as “is this site spammy?”. Features are the inputs. Things like content, links, or really anything that is indexed by a search engine can be a feature.
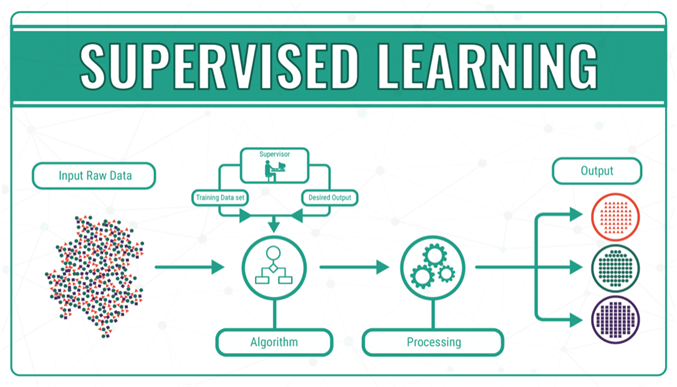
The fun part of machine learning is called “training”. Training involves creating or learning the “model”. This involves showing the model labeled examples and enabling the model to iteratively learn the relationships between the various features and labels. With machine learning, the training can also infer relationships that you never thought were there. This is called “inference”.
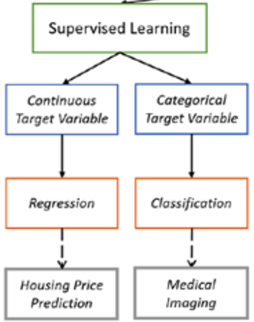
There are two types of models: regression and classification. A modern search engine like Google uses regression models mostly, but sometimes wraps all of that into larger-scale classification models. Regression models answer things like “what is the probability that this link is spam?” whereas classification models answer bigger questions like “is this site spam?”.
Google realized that they could merge humans and machine learning to quickly shift its rules-based algorithms to a machine learning-based version. It created a “Search Quality Rating Guidelines”, the sole purpose of which was to instruct human “quality raters” to label a web page as spam or not. Armed with this newly labeled data, and an already exhaustive list of features from the inputs into its existing rules-based algorithms, the training could begin.

This combines the old Yahoo! portal model, where humans rated the quality of web pages, with the scalability of the modern algorithmic search engine approach. It takes the pieces of a modern search engine, and builds a huge firewall by essentially making the rules of its algorithms a black box. Instead of artificially trying to exploit the loopholes of its algorithms, website owners now simply resorted to “not making a spammy site”.

Accordingly, the new version of optimizing a website to rank on Google made a seismic shift around 2013, although most of the search engine optimization (SEO) industry didn’t even notice until many years later. SEO software continued to parrot the same old rules-based infrastructure as a way to optimize a website or web page. In reality, the most accurate approach to optimizing needed to use a machine learning process itself!
Today’s successful SEO software platforms are machine learning models of a machine learning model. The labels are ranking data or search results, and the features are the algorithm outputs themselves. The modern SEO software should be drastically different than its old rules-based predecessors. Instead of trying to find loopholes and work against the interests of Google, the modern SEO software attempts to show how this regression-based machine learning process is occurring, leading the website owners to optimize exactly how Google wants them to.
 Ask The Search Engineer on Youtube!
Ask The Search Engineer on Youtube!