
The Search Engine Query Layer
To a search engineer, the query layer is simply the user interface to their machine. It is the layer that merges all of the carefully planned, pre-calculated data with a run-time query from a user. To non-search engineers, the query layer IS the search engine. Most of the time users have no idea of the other three layers that were needed to make it all happen.
Regardless, all of the work done to this point: the crawling, storing and indexing, and scoring — all of these things are useless without a good query layer in place to bring it all together. I won’t go into the specifics (programming languages, libraries, etc…) here, just the things I wish I had someone tell me when I built my first search engine.
The Inverted Index
One of the most important facets of a good query layer is the technology that is used to retrieve run-time scoring from a number of critical areas of both pre-calculated and raw data fields, and construct an index to retrieve them quickly and efficiently. We call each item in these indexes “documents”. Documents are made up of one or more fields, which can be anything: some examples are a META Title, the HTML on a web page, a basket of phrases that the search engine thinks a web page is about, or even the anchor text from an incoming link to a web page or website.
The documents are indexed into what we call an inverted index. Each document will belong to many inverted indexes. Inverted indexes take all the documents (and their fields) and split them into smaller pieces or “words”, building an index for each word. If a document has 1,000 words in it, there could be 1,000 inverted indexes built just as a starting point.
Many additional query algorithms will be used to either join multiple inverted indexes together (in the case of a simple intersection query between two or more query words) or even build new inverted indexes that are based on additional higher-level pre-calculated query algorithms that try to anticipate how a user may interact with the search engine query layer. In addition, pre-calculated areas of the search engine scoring layer will also be included in this query scoring process.
These indexes are built and then used at what we call “run-time”, or immediately as the user queries the search bar.
Run-Time Scoring Algorithms
As the user submits a query, there are a number of query scoring algorithms that are used to match the user’s query against the various documents in the inverted indexes, and then provide a ranking system that orders the most relevant results to the top.
There are four major components to a modern query scoring algorithm:
- Term Frequency measures how often a query word appears in a document. In the early days of search engine optimization, this was often a huge loophole. You could simply add tons of instances of the target words on a web page, and that web page would rank very well because of this component of the query algorithm.
- Inverse Document Frequency (IDF) measures how often the query word appears across the entire inverted index. This is kind of a peer-related check: how often does everyone else use this word? Is it a generally important word for everyone?
- Coordination measures how many query words that a document contains. If a user types in three words into the search bar, the query scoring algorithms will attempt to match documents that have all three of those words in them.
- Length Normalization measures how efficiently a query matches a document. A document that matches one word out of ten words will score better than a document that matches one word out of a hundred words.
These four major components will often be augmented by additional boost factors or other normalization factors on various fields, whole documents, and combinations thereof.
Tuning The Query Layer
The biases and weights on the run-time components of the search engine’s query layer are tuned by curating the search results in a way that provides the best user experience. In the early days of search, these biases and weights were the result of regression testing a corpus of queries against the search engine, and determining a global maximum solution that worked the best across many billions of different queries.
Today, these biases and weights are tuned by using neural networks. Quality searcher rating guidelines are presented to a team of humans. Those humans are shown comparisons between search results, and tasked with determining which search results are better. These humans are given a playbook of guidelines for which websites, web pages, links, etc… are good vs. bad.
These human curated ranking positions are then fed into a deep learning neural network. The neural network architecture has been designed to efficiently learn the relationship between the individual scoring layer algorithms (called the “features” of the neural network) and the human curated ranking positions (effectively the “labels”).
In modern search engines, this process is done on every major search result page to finely tune each user experience. The definition of major typically relates to head / tail keyword configurations. For instance, “buy a car” is going to get its own finely tuned biases and weights on each algorithm, but “buy a fast sports car” may just borrow these settings. It all depends on the search engineer’s (technical) resource budget.
Personalization
All of the crawling, indexing, scoring, and query design up to this point is useless if the user does not have a good experience. In order to ensure this, you have to add another sub-layer into the query layer, which is typically called personalization.
There are a number of things that drive personalization requirements, some of which are:
- The user’s location,
- The user’s search history,
- The user’s current social media connections and history,
- The user’s device, and
- The search engine’s knowledgebase.
Almost all of these personalization considerations are accomplished by altering the requested query. These requirements will drive new run-time query algorithms that will be available to query against if needed. Some of these query alterations are easy, but some can have implications all the way down to the crawling layer.
For instance, in order to push more local results to the user, first the crawling process must fetch and properly store the web server’s location. This doesn’t necessarily mean the web server’s IP address! One or more new algorithms will need to be created in the scoring layer that looks at the content and decides where this content is located. There are hreflang tags to look at, but the search engine ultimately should not depend on a human to decide.
In the end, search engine personalization creates a lot of noise for a search engineer. Instead of debugging one version of the search engine results, there can be hundreds of different types of search results for the same search.
Natural Language Processing (NLP)
One important feature of a search engine query layer architecture is natural language processing (NLP). It is the difference between your search engine acting like a ten year old vs. a college graduate. They may both understand the language, but one has no context and understanding of the language culture.
NLP was advanced considerably in 2013 by some researchers at Google. The Word2vec system allowed users to enter keywords into the search bar, and magically retrieve content that was related but they didn’t even search for. This was because words were now organized into a vector space.
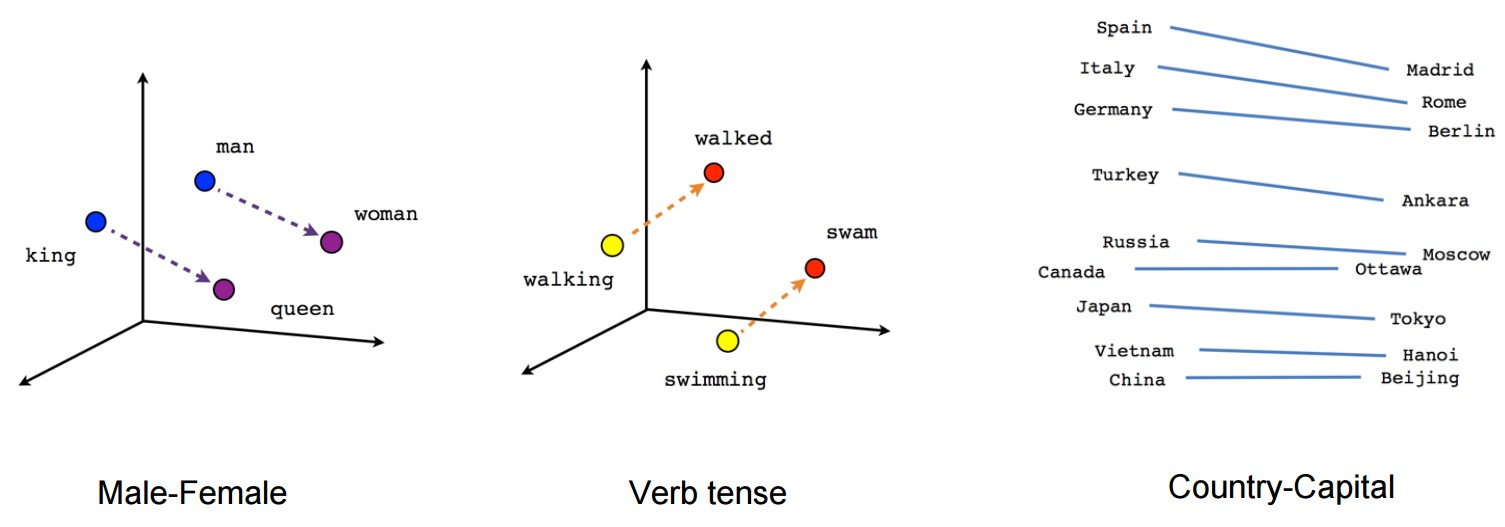
An overview of the Word2vec algorithm, a great attempt at NLP. Words are represented and grouped by a vector space.
In 2019, Google researchers advanced this area again, with BERT. Whereas Word2vec generates a single word embedding representation for each word in the vocabulary, BERT, a contextual NLP model, instead generates a representation of each word that is based on the other words in the sentence. For example, in Word2vec, the word “bank” would have the same context-free representation in “bank account” and “bank of the river.”
Contextual models instead generate a representation of each word that is based on the other words in the sentence. For example, in the sentence “I accessed the bank account,” a unidirectional contextual model would represent “bank” based on “I accessed the” but not “account.” However, BERT represents “bank” using both its previous and next context — “I accessed the … account” — starting from the very bottom of a deep neural network, making it deeply bidirectional.
All of these technologies are critical to a good user experience, and making the query layer seem like it is more human-like.
Discrete Search Results
It is possible to only retrieve specific types of content, thus creating a specific type of search engine. You could imagine retrieving only images or news-related content. These features can be available if you plan your other layers accordingly.
Some filters are easier than others. Images are typically labeled as such, or can be easily detected. However, a non-trivial scoring algorithm would need to be created that determines whether or not a particular URL is related to a news article or not.
The way a search engineer presents these discrete search results is also a design consideration. Do you present each as its own discrete section? Or do you blend them into universal search results?
The Query Parser
We have seen that the original query can often be altered depending on NLP or if we are requesting a discrete set of results like images or news. This means that the query parser, or the software responsible for taking the contents of the search bar and turning it into instructions for the query layer algorithms, must be feature rich and flexible.
A query parser typically breaks up a query into terms and operators. Terms can be one or more words, and can be combined with Boolean operators to create complex queries.
Each term can be ran against any number of fields like the META Title, HTML or even pre-calculated data. A query parser may request something like this: “title: used cars html: used cars” indicating that the search returns only documents that have “used cars” in both the META Title and the HTML content.
Advanced query parsers will allow for things like wildcard searches (“used car*”), fuzzy matching (“used cars~”), proximity search (“used cars~10”), range search (“mod_date:[20020101 TO 20030101]”), boosted terms (“used^4 cars”), and many more flexible paradigms that allow users to find exactly what they are looking for. And of course, your query parser must have its own special escape characters, when users are searching for something that is used as a feature (e.g. “~*?^][”).
It is important to design the query parser not only based on what the user may want, but also what your NLP and personalization architecture dictates. Suppose a user types in “used sports cars” from downtown Boston, MA. Your search engine, trying to provide only used sports cars results in the local Boston area, may want to allow for a geographic field search that takes a longitude and latitude, and provides a distance minimizing algorithm.
At the same time, you may also want to hide this feature from manual input, and rely on your personalization algorithms to take care of this (e.g. transforming a query like “used sports cars in Boston” into “html: used sports cars location: 42.3601 N, 71.0589 W”).
Other features, like discrete results, will require you to create higher level fields like “news:” or “image:”. If a user wants to return only images in their search, they may type in “image: used sports cars”.
Summary
From a search engineer’s perspective, building a search engine query layer is in many ways the most complicated part of building a search engine. It requires that many moving parts come together, and that typically means lots of unplanned design iteration on the layers below.
The query layer is a complex puzzle that must look simple to the user. It must take millions of calculations come together in a few milliseconds. It must be flexible enough that a user can specify distinct changes to its query, but smart enough to know what the user really is asking.
The query layer is the interface between human and machine. It is responsible for taking human intent and converting it into a machine readable instruction, and then taking that machine result and converting it back into a human readable result. With over 80 different character sets, and hundreds of different countries and cultures, it is the edge case of search.
A good search engineering team will understand the challenges of a query layer and approach accordingly. It requires a special mind to be able to think in both the machine world and the human world; in fact, most conventional software teams split these tasks. You will typically have user interface experts on one side, and back-end server experts on the other. The query layer requires these two teams to merge their thinking.
 Ask The Search Engineer on Youtube!
Ask The Search Engineer on Youtube!